
Breaking Nvidia Monopoly: How GLM-Image and Huawei''s Ascend Chip Topped the Global AI Charts
On January 14, a seismic shift occurred in the global artificial intelligence landscape, catching the attention of both industrial players and capital markets worldwide. GLM-Image, a multimodal image generation model jointly developed by Zhipu AI and Huawei, ascended to the number one spot on the Hugging Face Trending list.
For the uninitiated, Hugging Face is essentially the "World Expo" of open-source models—a central hub where international giants and developers alike showcase their best AI tools. Topping its Trending list is akin to taking center stage at the world's premier tech conference, signifying international recognition of GLM-Image's technical prowess and application value.
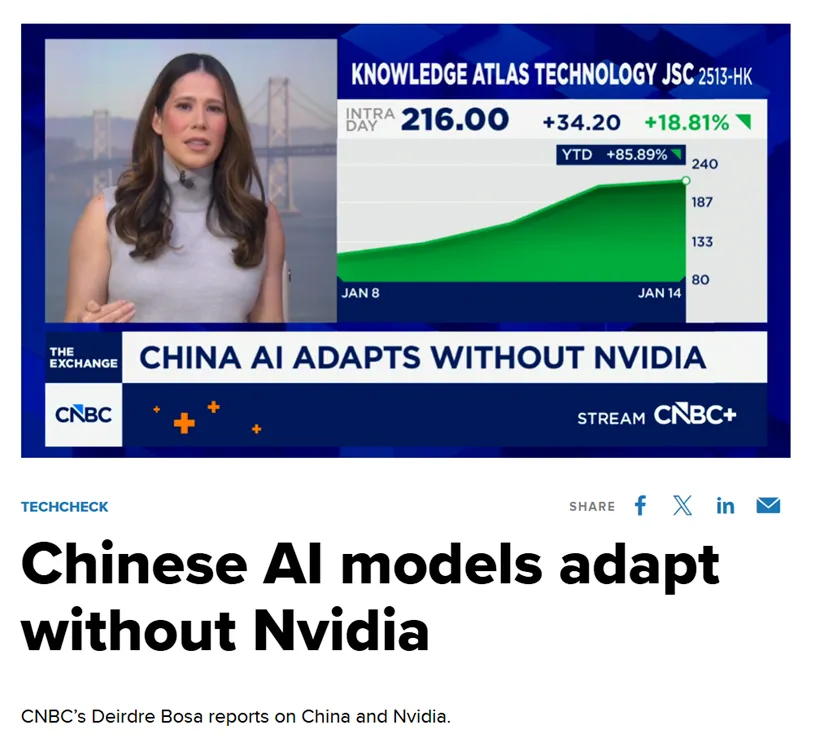
U.S. media outlet CNBC noted that this advanced model, trained by Zhipu and Huawei, effectively "breaks the myth" of reliance on U.S. chips. This achievement is not accidental; it is the inevitable result of deep "software-hardware synergy" and a breakthrough across the entire domestic AI industrial chain in China.
The "Full-Stack" Foundation: Huawei Ascend & MindSpore
The critical support behind this achievement is the domestic computing power foundation built by Huawei.
Unlike most previous AI models that relied heavily on foreign GPUs (primarily Nvidia) for training, GLM-Image ran its entire lifecycle—from data preprocessing to massive-scale training—on Huawei's Ascend 800T A2 chips and the MindSpore AI framework.
This fully autonomous "hardware + framework" combination is the real story here. It addresses the core "chokepoint" problem in AI development, proving that training state-of-the-art (SOTA) models is possible without relying on the CUDA ecosystem. The Ascend 910B series (which powers the 800T A2) has demonstrated formidable performance in large cluster environments, offering a viable alternative for the global open-source community.
Deconstructing the Architecture: Why AR + Diffusion Matters
Zhipu AI also achieved significant innovation in the model's architecture. GLM-Image departed from the standard technical routes used by many Western open-source models.
Instead, it utilizes a hybrid "Autoregressive (AR) + Diffusion Decoder" architecture.
- The "Brain" (Autoregressive): A 9B parameter AR model handles understanding complex instructions, layout planning, and text generation within images.
- The "Painter" (Diffusion): A 7B parameter diffusion model acts as the decoder, filling in high-fidelity details based on the AR model's blueprint.
This approach solves a notorious pain point in AI image generation: rendering accurate text. Previously, AI-generated images often featured garbled, unreadable text. Thanks to the AR component's strong cognitive capabilities, GLM-Image achieved the highest accuracy in Chinese character generation among open-source models.
This technical path—prioritizing cognitive understanding before generation—mirrors the approach seen in advanced cognitive reasoning models like Nano Banana Pro, which centers on "knowledge + reasoning" to handle complex tasks with greater precision than standard generative models.
Market Reaction: The Rise of Knowledge Atlas (2513.HK)
The "gold standard" value of topping the global chart was immediately reflected in capital market reactions. When news of GLM-Image's open-sourcing first broke, the stock price of Zhipu AI's parent entity, Knowledge Atlas (2513.HK), surged over 16% in a single day. Investors clearly recognized the long-term value of the "domestic chip + autonomous model" combination.
In fact, since listing on the Hong Kong Stock Exchange on January 8 as the "first global large model stock," Knowledge Atlas has seen its share price increase by over 100%.
Democratizing AI Design: Open Source for All
From a long-term perspective, GLM-Image's success is driven by the synergy of an entire industrial chain. This full-chain capability doesn't just serve tech giants; it significantly lowers barriers for small and medium-sized enterprises (SMEs).
With inference costs as low as RMB 0.1 (approx. $0.01 USD) per image, GLM-Image allows businesses to utilize top-tier AI design tools at a fraction of traditional costs.
Today, the open-source code and weights for GLM-Image are available synchronously on both GitHub and Hugging Face. Developers worldwide can now freely use this "fully autonomous solution," breaking the traditional narrative that cutting-edge model training depends solely on US silicon.
Seedance 2.0 Pricing Revealed: Is the 1 RMB/Sec Cost the Death of Sora 2?
ByteDance's Seedance 2.0 pricing is here: 1 RMB per second for high-quality AI video. Discover how this cost structure challenges Sora 2 and reshapes the industry.

Why Seedance 2.0 Was Removed? The Truth Behind StormCrew's Video & Kling 3.0's Defeat
StormCrew's review caused a panic ban of Seedance 2.0. Discover why its 10x cost-effectiveness and distillation tech are crushing Kling 3.0 in AI video.

Kling 3 Just Dropped: Will Wan 3 Be the Next Big Shock? (The AI Video Arms Race)
The AI video war is heating up. With Kling 3 setting a new standard, we analyze the rivalry, the history of the Audio Battles, and predict what Wan 3 needs to do to survive.
Kling 3 4K vs Pro (1080p): When 4K Is Worth It-and When It's Not
A practical decision framework for choosing Kling 3 4K vs Pro (1080p): when 4K improves detail, motion, and compression-and when 1080p is the smarter default.
Kling 3 4K Workflow: Prompts, Shot Planning, and Export Settings That Actually Hold Up
A repeatable Kling 3 4K workflow to get usable deliverables: two-pass iteration, prompt templates, safe complexity rules, and export guidance to survive platform recompression.
Kling 3 Native 4K: What It Means for Quality, Motion, Compression, and Real-World Use
Learn what Kling 3 native 4K changes vs 1080p: sharper detail, cleaner motion, fewer artifacts, and when 4K is actually worth it.
HappyHorse AI Video Generator: What the New Model Can Do
Discover HappyHorse, a new AI video generation model with text-to-video, image-to-video, video-to-video, native audio, and creator-friendly workflows.

Wan 2.7 Image Meets Kling 2.6: The Ultimate AI Visual Workflow
Discover how the new Wan 2.7 Image model's advanced editing and 3K text rendering capabilities create the perfect asset pipeline for Kling 2.6 video generation.