
Briser le monopole de Nvidia : Comment GLM-Image et la puce Ascend de Huawei ont conquis les classements IA
Le 14 janvier, un changement sismique s'est produit dans le paysage mondial de l'intelligence artificielle, attirant l'attention des acteurs industriels et des marchés financiers du monde entier. GLM-Image, un modèle de génération d'images multimodal développé conjointement par Zhipu AI et Huawei, s'est hissé à la première place de la liste Trending (tendances) de Hugging Face.
Pour les non-initiés, Hugging Face est essentiellement « l'Exposition Universelle » des modèles open source — un hub central où les géants internationaux et les développeurs présentent leurs meilleurs outils d'IA. Atteindre le sommet de sa liste Trending équivaut à occuper la scène principale de la plus grande conférence technologique mondiale, signifiant la reconnaissance internationale des prouesses techniques et de la valeur applicative de GLM-Image.
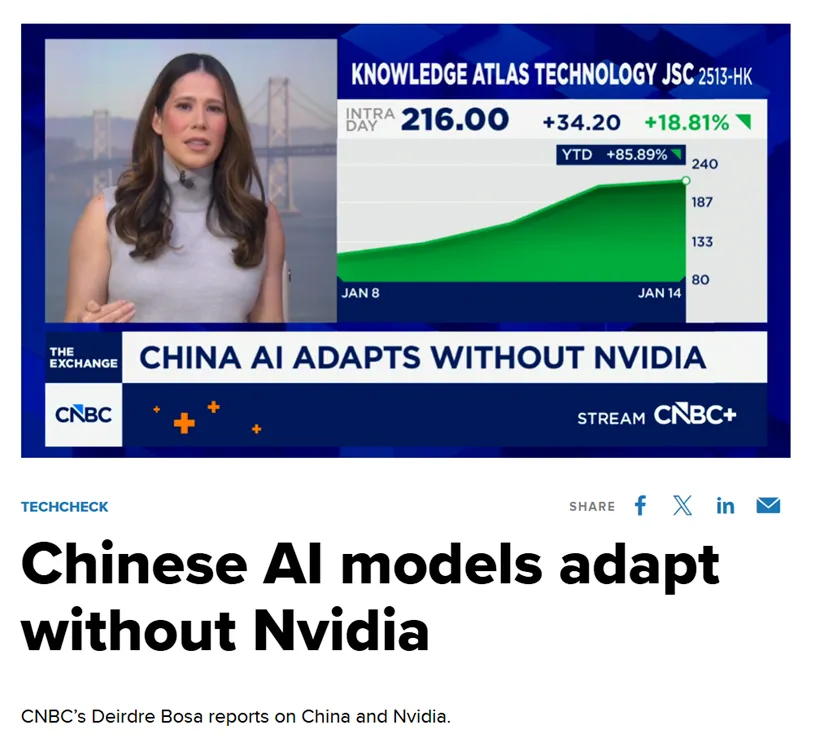
Le média américain CNBC a noté que ce modèle avancé, entraîné par Zhipu et Huawei, « brise efficacement le mythe » de la dépendance aux puces américaines. Cette réussite n'est pas accidentelle ; elle est le résultat inévitable d'une profonde « synergie logiciel-matériel » et d'une percée dans toute la chaîne industrielle nationale de l'IA en Chine.
La fondation « Full-Stack » : Huawei Ascend & MindSpore
Le soutien critique derrière cette réussite est la fondation de puissance de calcul nationale construite par Huawei.
Contrairement à la plupart des modèles d'IA précédents qui dépendaient fortement des GPU étrangers (principalement Nvidia) pour l'entraînement, GLM-Image a exécuté l'intégralité de son cycle de vie — du prétraitement des données à l'entraînement à grande échelle — sur les puces Huawei Ascend 800T A2 et le framework d'IA MindSpore.
Cette combinaison totalement autonome « matériel + framework » est la véritable information ici. Elle résout le problème central du « goulot d'étranglement » dans le développement de l'IA, prouvant que l'entraînement de modèles de pointe (SOTA) est possible sans dépendre de l'écosystème CUDA. La série Ascend 910B (qui propulse le 800T A2) a démontré des performances redoutables dans les environnements de grands clusters, offrant une alternative viable à la communauté open source mondiale.
Déconstruction de l'architecture : Pourquoi AR + Diffusion est important
Zhipu AI a également réalisé une innovation significative dans l'architecture du modèle. GLM-Image s'est écarté des voies techniques standard utilisées par de nombreux modèles open source occidentaux.
Au lieu de cela, il utilise une architecture hybride « Autorégressif (AR) + Décodeur de Diffusion ».
- Le « Cerveau » (Autorégressif) : Un modèle AR de 9 milliards (9B) de paramètres gère la compréhension des instructions complexes, la planification de la mise en page et la génération de texte dans les images.
- Le « Peintre » (Diffusion) : Un modèle de diffusion de 7 milliards (7B) de paramètres agit comme décodeur, remplissant des détails haute fidélité basés sur le plan du modèle AR.
Cette approche résout un problème notoire dans la génération d'images par IA : le rendu précis du texte. Auparavant, les images générées par IA présentaient souvent un texte brouillé et illisible. Grâce aux fortes capacités cognitives du composant AR, GLM-Image a atteint la plus haute précision dans la génération de caractères chinois parmi les modèles open source.
Cette voie technique — priorisant la compréhension cognitive avant la génération — reflète l'approche observée dans les modèles de raisonnement cognitif avancés comme Nano Banana Pro, qui se concentre sur « connaissance + raisonnement » pour gérer des tâches complexes avec une plus grande précision que les modèles génératifs standard.
Réaction du marché : L'ascension de Knowledge Atlas (2513.HK)
La valeur « étalon-or » d'être en tête du classement mondial s'est immédiatement reflétée dans les réactions du marché des capitaux. Lorsque la nouvelle de la mise en open source de GLM-Image a éclaté, le cours de l'action de l'entité mère de Zhipu AI, Knowledge Atlas (2513.HK), a bondi de plus de 16 % en une seule journée. Les investisseurs ont clairement reconnu la valeur à long terme de la combinaison « puce nationale + modèle autonome ».
En fait, depuis son introduction à la Bourse de Hong Kong le 8 janvier en tant que « première action mondiale de grand modèle », Knowledge Atlas a vu le prix de son action augmenter de plus de 100 %.
Démocratiser le design IA : L'Open Source pour tous
Dans une perspective à long terme, le succès de GLM-Image est porté par la synergie de toute une chaîne industrielle. Cette capacité de chaîne complète ne sert pas seulement les géants de la technologie ; elle abaisse considérablement les barrières pour les petites et moyennes entreprises (PME).
Avec des coûts d'inférence aussi bas que 0,1 RMB (env. 0,01 USD) par image, GLM-Image permet aux entreprises d'utiliser des outils de conception IA de premier plan à une fraction des coûts traditionnels.
Aujourd'hui, le code source et les poids de GLM-Image sont disponibles de manière synchrone sur GitHub et Hugging Face. Les développeurs du monde entier peuvent désormais utiliser librement cette « solution totalement autonome », brisant le récit traditionnel selon lequel l'entraînement de modèles de pointe dépend uniquement du silicium américain.

Pourquoi Seedance 2.0 a été banni ? La vérité sur la vidéo de StormCrew & la défaite de Kling 3.0
L'avis de StormCrew a provoqué le bannissement panique de Seedance 2.0. Découvrez pourquoi sa rentabilité x10 et sa technologie de distillation écrasent Kling 3.0.

Kling 3 Just Dropped: Will Wan 3 Be the Next Big Shock? (The AI Video Arms Race)
La guerre de la vidéo par IA s''intensifie. Avec Kling 3 établissant un nouveau standard, nous analysons la rivalité, l''histoire des batailles audio, et prédisons ce que Wan 3 doit faire pour survivre.
Kling 3 4K vs Pro (1080p) : quand le 4K vaut le coup (et quand ce n'est pas le cas)
Cadre de décision pratique pour choisir Kling 3 4K vs Pro (1080p) : quand le 4K ameliore detail, mouvement et compression, et quand le 1080p est le bon choix.
Kling 3 4K workflow : prompts, preparation des plans, et export qui tiennent vraiment
Kling 3 4K workflow reproductible : itération en deux passes, templates de prompt, regles de complexite, et export pour survivre a la recompression.
Kling 3 native 4K : ce que cela change pour la qualité, le mouvement, la compression et l'usage réel
Comprendre ce que Kling 3 native 4K change face au 1080p : details plus nets, mouvement plus propre, moins d'artefacts, et quand le 4K vaut vraiment le coup.
HappyHorse AI Video Generator : ce que peut faire ce nouveau modèle
Découvrez HappyHorse, un nouveau modèle de génération vidéo avec text-to-video, image-to-video, video-to-video, audio natif et des workflows pensés pour les créateurs.

Wan 2.7 Image Meets Kling 2.6: The Ultimate AI Visual Workflow
Découvrez comment les capacités avancées d'édition et de rendu de texte 3K du nouveau modèle Wan 2.7 Image créent le pipeline d'actifs parfait pour la génération de vidéos Kling 2.6.
The Next Generation of Generation: Unpacking the Wan 2.7 Upgrade
The highly anticipated Wan 2.7 Video release marks a turning point, introducing a multi-modal injection system and a studio-grade workflow for creators.