
Google Veo 3.1 深度评测:4K 原生画质与角色一致性的革命
引言
长期以来,AI 视频生成领域一直饱受三大顽疾的困扰:分辨率限制、长宽比约束以及角色一致性问题。Google Veo 3.1 同时解决了这三个问题,标志着 AI 视频技术演进的重要里程碑。
Google Veo 3.1 代表了 Google 迄今为止最雄心勃勃的视频生成模型,它带来了原生 4K 分辨率、9:16 竖屏视频支持以及突破性的身份一致性 (Identity Consistency) 能力。这些功能共同解决了内容创作者、电影制作人和社交媒体专业人士最常见的痛点。
在这篇深度评测中,我们将探讨:
- 原生 4K 上变换如何消除对外部放大工具的需求
- 9:16 竖屏视频对“移动优先”内容创作的影响
- 用于角色锁定的革命性身份一致性 (Identity Consistency) 引擎
- 由 Bedros Pamboukian 发现的 Veo 3.2 泄露模型代码抢先看
清晰度的革命:原生 4K 上变换
打破分辨率壁垒
以往的 AI 视频模型通常仅支持最高 1080p 分辨率,用户不得不使用第三方放大工具来实现 4K 画质。Google Veo 3.1 改变了这一范式,它通过 API 提供原生 4K 输出,直接在生成过程中交付前所未有的清晰度和细节。
技术实现: 这种 4K 能力是通过多阶段生成过程实现的,该过程结合了高分辨率潜在扩散与时间连贯性算法。与简单的放大不同,Veo 3.1 的原生 4K 生成能够保持帧与帧之间的细节一致性,消除了后期处理放大中常见的伪影和模糊现象。
文件大小与质量考量
Veo 3.1 的 4K 输出有一个值得注意的方面,那就是巨大的文件体积。一段 8 秒的 4K 视频大小可达约 50MB,这反映了其高比特率和画质保留程度。
这一文件大小表明:
- 高质量压缩:在保持视觉保真度的同时进行高效编码
- 丰富的细节保留:极少的压缩伪影
- 专业工作流兼容性:适用于广播和电影级应用
[!TIP] 优化 4K 工作流:在使用 Google Veo 3.1 生成 4K 内容时,请考虑您的存储需求和带宽限制。高质量的输出伴随着更大的文件体积,因此请相应地规划您的存储策略。
移动优先:原生 9:16 竖屏生成
告别手动裁剪
对于社交媒体创作者来说,从横屏到竖屏视频的转换一直是个挑战。传统的 AI 视频生成器主要输出 16:9 的内容,迫使创作者必须手动裁剪或使用复杂的编辑工作流,以适应 TikTok、Instagram Reels 和 YouTube Shorts 等平台。
Veo 3.1 的 9:16 原生支持消除了这种摩擦,它生成的视频专门为移动端消费进行了优化。该模型理解竖屏构图原则,确保关键视觉元素保持居中,并在 9:16 的长宽比内正确取景。
构图智能
Veo 3.1 的独特之处在于它对竖屏构图动态的理解。该模型会自动:
- 将主体居中于垂直画面内
- 优化文本位置以适应移动端阅读
- 在垂直空间中保持视觉层级
这种智能构图消除了竖屏内容创作中的盲猜环节,让创作者能够专注于叙事而非技术调整。
圣杯:身份一致性 (Identity Consistency)
解决角色一致性难题
AI 视频生成中最具挑战性的方面之一,就是在不同的镜头和场景中保持角色身份的一致性。以往的模型往往难以维持面部特征、服装细节和整体外观的一致,限制了其在叙事内容中的实用性。

Veo 3.1 的身份一致性 (Identity Consistency) 引擎引入了一种突破性的方法来解决这个问题。通过允许用户上传角色的多张参考图像,模型可以在生成的序列中“锁定”特定的面部特征、服装元素和身体特征。
身份锁定如何工作
一致性系统通过以下关键机制运行:
- 多参考图处理:用户可以上传多张参考图像(例如来自不同角度)
- 特征提取与映射:模型识别并映射关键的面部特征点
- 时间连贯性执行:在帧与场景之间保持一致性
这项技术使创作者能够:
- 在不同环境中生成同一角色的多个镜头
- 在不同摄像机角度下保持外观一致
- 创建具有常驻角色的连贯叙事序列
工作流:从静态图像到 4K 竖屏视频
端到端制作流程
结合 Veo 3.1 的三大核心功能,我们可以实现以前在 AI 视频工具中无法想象的流线型制作工作流。以下是制作专业竖屏内容的理论工作流:
第一步:角色准备
- 收集主体的高质量参考图像
- 确保图像展示了不同的角度和表情
- 上传参考图以建立身份一致性
第二步:提示词工程 (Prompt Engineering)
- 撰写包含竖屏构图提示的详细 Prompt
- 指定 4K 分辨率和 9:16 长宽比
- 包含角色一致性参数
第三步:生成与审查
- 生成初始序列
- 审查一致性和质量
- 进行迭代改进
第四步:最终输出
- 导出原生 4K 竖屏视频
- 无需额外的放大或裁剪
- 准备好直接上传至社交平台
下一步是什么?Veo 3.2 抢先看
代码泄露发现
虽然 Veo 3.1 代表了重大进步,但有证据表明 Google 已经在开发下一个迭代版本。研究人员 Bedros Pamboukian 最近在 Google 的代码库中发现了对 VIDEO_GENERATION_VE03 的引用,这表明 Veo 3.2 正处于积极开发中。
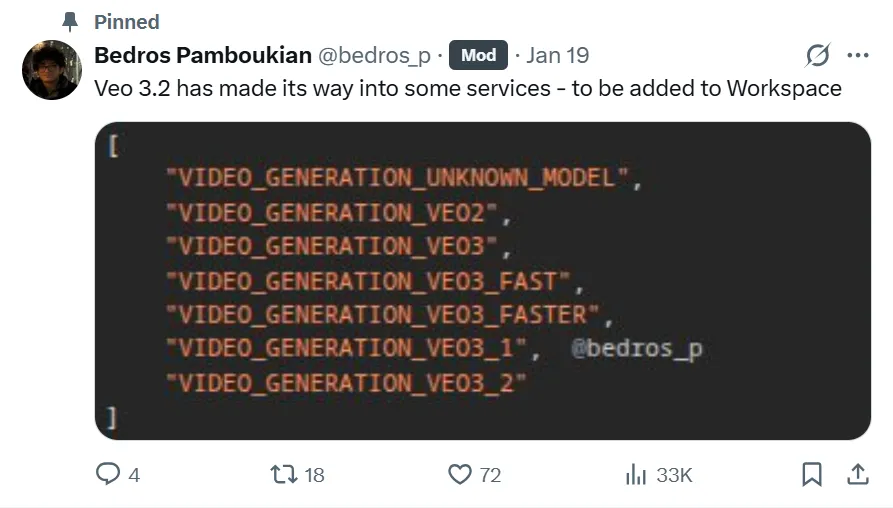
来源:Bedros Pamboukian via X
已知与未知
VIDEO_GENERATION_VE03 的发现证实了 Google 将继续在视频生成技术上进行巨额投资。然而,区分既定事实与猜测非常重要:
已确认信息:
- Google 正在积极开发新的视频生成模型
- 内部代号表明它是 Veo 3.1 的继任者
- 截至发现之日,开发工作仍在进行中
未知因素:
- 具体的功能改进或新能力
- 发布时间表和可用性
- 定价结构和访问权限
负责任的推测
基于 Google 的开发模式以及从 Veo 1.0 到 3.1 的演进,我们可以合理预期 Veo 3.2 将专注于增强时间连贯性和提高效率。然而,必须强调的是,这些只是基于行业趋势的猜测,并非已确认的功能。
结语
Google Veo 3.1 代表了 AI 视频生成技术的分水岭时刻。通过同时解决分辨率限制、长宽比约束和角色一致性问题,Google 创造了一款真正满足专业内容创作者需求的工具。
关键要点:
- 原生 4K 消除了对放大的依赖,直接从生成端提供广播级画质
- 9:16 竖屏视频支持简化了移动端内容的创作工作流
- 身份一致性 (Identity Consistency) 解决了 AI 视频中最持久的挑战之一
- 发现的 Veo 3.2 代码预示着该领域将持续快速创新
对于那些一直等待 AI 视频技术成熟以用于专业应用的创作者来说,Veo 3.1 很可能就是那个转折点。随着技术的不断演进,我们可以期待更多精密工具的涌现。但就目前而言,Veo 3.1 依然是获取高质量、一致性 AI 视频的最全面解决方案。
Kling 3 4k Vs Pro
SEO-friendly description for search engines
Kling 3 4k Workflow
SEO-friendly description for search engines
Kling 3 Native 4k
SEO-friendly description for search engines
HappyHorse AI 视频生成模型:这款新模型能做什么
了解 HappyHorse 这款新的视频生成模型,支持 text-to-video、image-to-video、video-to-video、原生音频与更适合创作者的工作流。

Wan 2.7 Image Meets Kling 2.6: The Ultimate AI Visual Workflow
探索全新 Wan 2.7 Image 模型的高级编辑和 3K 文本渲染功能如何为 Kling 2.6 视频生成打造完美的资产工作流。
The Next Generation of Generation: Unpacking the Wan 2.7 Upgrade
The highly anticipated Wan 2.7 Video release marks a turning point, introducing a multi-modal injection system and a studio-grade workflow for creators.
音画同步实战指南:Kling Video 3.0 Omni 对口型深度教程
Kling Video 3.0 Omni 原生视听能力完整攻略。学习如何实现精准对口型、音画同步直出、复杂情感再现,打造专业级AI视频内容。
零成本动捕棚实战指南:用 Kling 3.0 动作控制打造极限动作物理
掌握 Kling 3.0 极限动作 AI,学习如何零成本创建影视级战斗编排、跑酷动作无缝迁移和 VFX 级动画,彻底告别面条手和肢体融化。