
Rompiendo el monopolio de Nvidia: Cómo GLM-Image y el chip Ascend de Huawei conquistaron los rankings de IA
El 14 de enero, se produjo un cambio sísmico en el panorama global de la inteligencia artificial, captando la atención tanto de los actores industriales como de los mercados de capitales de todo el mundo. GLM-Image, un modelo de generación de imágenes multimodal desarrollado conjuntamente por Zhipu AI y Huawei, ascendió al primer puesto en la lista de tendencias (Trending) de Hugging Face.
Para los no iniciados, Hugging Face es esencialmente la "Exposición Universal" de los modelos de código abierto: un centro neurálgico donde gigantes internacionales y desarrolladores muestran sus mejores herramientas de IA. Encabezar su lista de tendencias es comparable a ocupar el escenario principal en la conferencia tecnológica más importante del mundo, lo que significa el reconocimiento internacional de la destreza técnica y el valor de aplicación de GLM-Image.
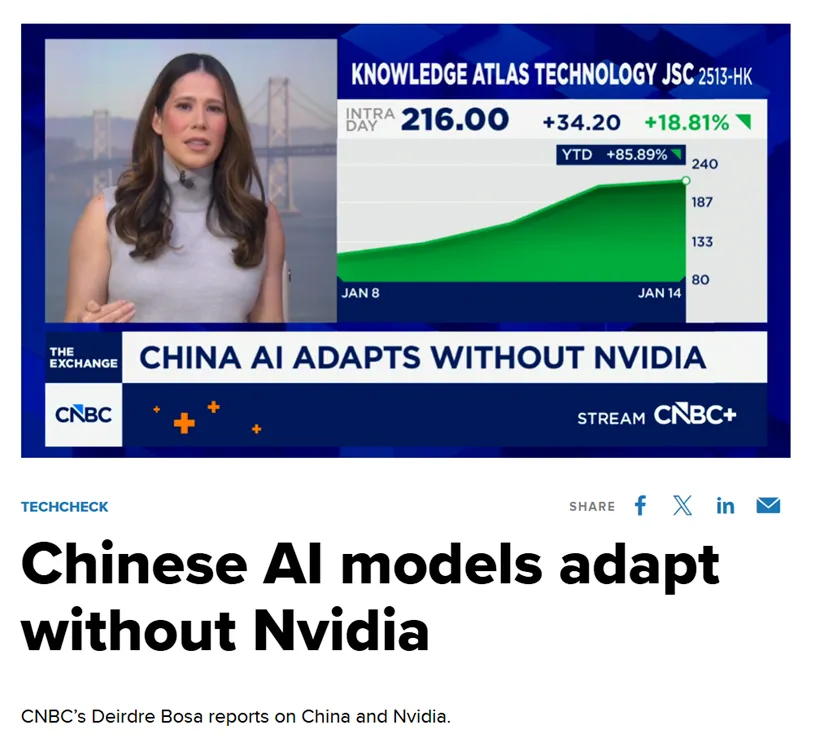
El medio estadounidense CNBC señaló que este modelo avanzado, entrenado por Zhipu y Huawei, efectivamente "rompe el mito" de la dependencia de los chips estadounidenses. Este logro no es accidental; es el resultado inevitable de una profunda "sinergia software-hardware" y un avance en toda la cadena industrial nacional de IA en China.
La base "Full-Stack": Huawei Ascend y MindSpore
El soporte crítico detrás de este logro es la base de potencia de cómputo nacional construida por Huawei.
A diferencia de la mayoría de los modelos de IA anteriores que dependían en gran medida de GPU extranjeras (principalmente Nvidia) para el entrenamiento, GLM-Image ejecutó todo su ciclo de vida —desde el preprocesamiento de datos hasta el entrenamiento a gran escala— en chips Huawei Ascend 800T A2 y el framework de IA MindSpore.
Esta combinación totalmente autónoma de "hardware + framework" es la verdadera noticia aquí. Aborda el problema central de "cuello de botella" en el desarrollo de IA, demostrando que entrenar modelos de vanguardia (SOTA) es posible sin depender del ecosistema CUDA. La serie Ascend 910B (que impulsa el 800T A2) ha demostrado un rendimiento formidable en entornos de clústeres grandes, ofreciendo una alternativa viable para la comunidad global de código abierto.
Deconstruyendo la arquitectura: Por qué importa AR + Difusión
Zhipu AI también logró una innovación significativa en la arquitectura del modelo. GLM-Image se apartó de las rutas técnicas estándar utilizadas por muchos modelos occidentales de código abierto.
En su lugar, utiliza una arquitectura híbrida de "Autoregresivo (AR) + Decodificador de Difusión".
- El "Cerebro" (Autoregresivo): Un modelo AR de 9 mil millones (9B) de parámetros maneja la comprensión de instrucciones complejas, la planificación del diseño y la generación de texto dentro de las imágenes.
- El "Pintor" (Difusión): Un modelo de difusión de 7 mil millones (7B) de parámetros actúa como decodificador, rellenando detalles de alta fidelidad basados en el plano del modelo AR.
Este enfoque resuelve un punto doloroso notorio en la generación de imágenes por IA: la renderización precisa de texto. Anteriormente, las imágenes generadas por IA a menudo presentaban texto ilegible o distorsionado. Gracias a las fuertes capacidades cognitivas del componente AR, GLM-Image logró la mayor precisión en la generación de caracteres chinos entre los modelos de código abierto.
Esta ruta técnica —priorizar la comprensión cognitiva antes de la generación— refleja el enfoque visto en modelos avanzados de razonamiento cognitivo como Nano Banana Pro, que se centra en "conocimiento + razonamiento" para manejar tareas complejas con mayor precisión que los modelos generativos estándar.
Reacción del mercado: El auge de Knowledge Atlas (2513.HK)
El valor de "estándar de oro" de encabezar la lista mundial se reflejó inmediatamente en las reacciones del mercado de capitales. Cuando se conoció la noticia de la apertura del código de GLM-Image, el precio de las acciones de la entidad matriz de Zhipu AI, Knowledge Atlas (2513.HK), subió más del 16% en un solo día. Los inversores reconocieron claramente el valor a largo plazo de la combinación "chip nacional + modelo autónomo".
De hecho, desde su salida a la Bolsa de Hong Kong el 8 de enero como la "primera acción global de modelos grandes", Knowledge Atlas ha visto aumentar el precio de sus acciones en más del 100%.
Democratizando el diseño con IA: Código abierto para todos
Desde una perspectiva a largo plazo, el éxito de GLM-Image está impulsado por la sinergia de toda una cadena industrial. Esta capacidad de cadena completa no solo sirve a los gigantes tecnológicos; reduce significativamente las barreras para las pequeñas y medianas empresas (PYMES).
Con costos de inferencia tan bajos como 0.1 RMB (aprox. 0.01 USD) por imagen, GLM-Image permite a las empresas utilizar herramientas de diseño de IA de primer nivel a una fracción de los costos tradicionales.
Hoy, el código fuente y los pesos de GLM-Image están disponibles sincrónicamente en GitHub y Hugging Face. Los desarrolladores de todo el mundo ahora pueden usar libremente esta "solución totalmente autónoma", rompiendo la narrativa tradicional de que el entrenamiento de modelos de vanguardia depende únicamente del silicio estadounidense.

¿Por qué eliminaron Seedance 2.0? La verdad tras el vídeo de StormCrew y la derrota de Kling 3.0
La reseña de StormCrew provocó la prohibición por pánico de Seedance 2.0. Descubre por qué su rentabilidad 10x y tecnología de destilación están aplastando a Kling 3.0.

Kling 3 Just Dropped: Will Wan 3 Be the Next Big Shock? (The AI Video Arms Race)
La guerra del video con IA se está caldeando. Con Kling 3 estableciendo un nuevo estándar, analizamos la rivalidad, la historia de las Batallas de Audio, y predecimos qué necesita hacer Wan 3 para sobrevivir.
Kling 3 4K vs Pro (1080p): cuando 4K vale la pena (y cuando no)
Marco de decision para Kling 3 4K vs Pro (1080p): cuando 4K mejora detalle, movimiento y compresion, y cuando 1080p es mejor.
Kling 3 4K workflow: prompts, plan de planos y export que aguanta de verdad
Un Kling 3 4K workflow repetible: iteracion en dos pases, templates de prompt, reglas de complejidad y export para recompression.
Kling 3 native 4K: que cambia en calidad, movimiento, compresion y uso real
Que cambia Kling 3 native 4K frente a 1080p: mas detalle, movimiento mas limpio, menos artefactos y cuando 4K vale la pena.
HappyHorse AI Video Generator: qué puede hacer el nuevo modelo
Descubre HappyHorse, un nuevo modelo de generación de video con text-to-video, image-to-video, video-to-video, audio nativo y flujos pensados para creadores.

Wan 2.7 Image Meets Kling 2.6: The Ultimate AI Visual Workflow
Descubra cómo las capacidades avanzadas de edición y renderizado de texto 3K del nuevo modelo Wan 2.7 Image crean la canalización de activos perfecta para la generación de video de Kling 2.6.
The Next Generation of Generation: Unpacking the Wan 2.7 Upgrade
The highly anticipated Wan 2.7 Video release marks a turning point, introducing a multi-modal injection system and a studio-grade workflow for creators.