
Quebrando o monopólio da Nvidia: Como o GLM-Image e o chip Ascend da Huawei conquistaram os rankings de IA
Em 14 de janeiro, ocorreu uma mudança sísmica no cenário global de inteligência artificial, capturando a atenção tanto de players industriais quanto dos mercados de capitais em todo o mundo. GLM-Image, um modelo de geração de imagem multimodal desenvolvido conjuntamente pela Zhipu AI e Huawei, ascendeu ao primeiro lugar na lista Trending do Hugging Face.
Para os não iniciados, o Hugging Face é essencialmente a "Expo Mundial" de modelos de código aberto — um hub central onde gigantes internacionais e desenvolvedores exibem suas melhores ferramentas de IA. Chegar ao topo de sua lista Trending é como ocupar o palco principal na principal conferência de tecnologia do mundo, significando o reconhecimento internacional da proeza técnica e do valor de aplicação do GLM-Image.
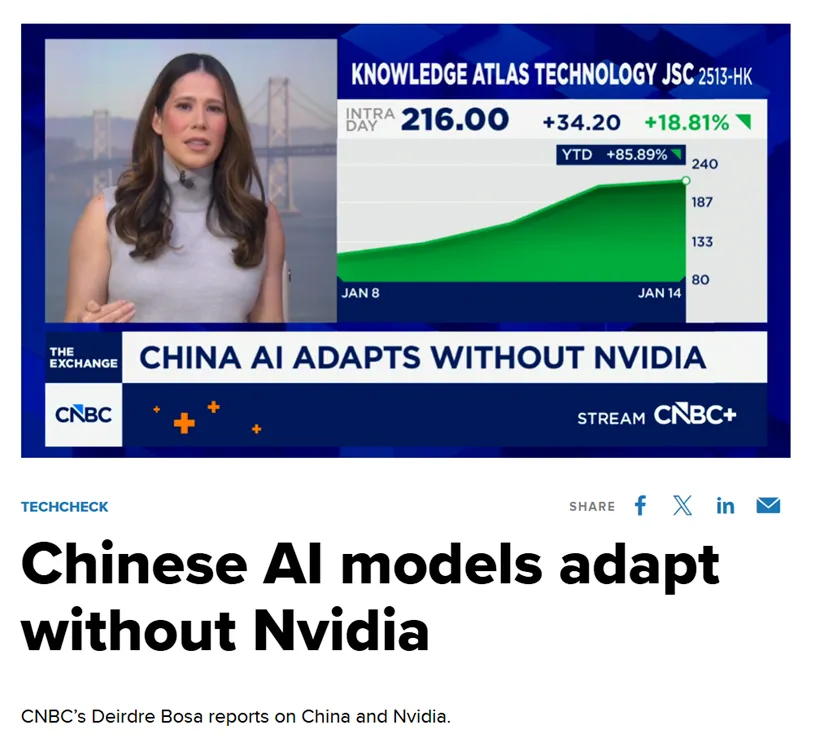
O canal de mídia dos EUA CNBC observou que este modelo avançado, treinado pela Zhipu e Huawei, efetivamente "quebra o mito" da dependência de chips dos EUA. Essa conquista não é acidental; é o resultado inevitável de uma profunda "sinergia software-hardware" e um avanço em toda a cadeia industrial doméstica de IA na China.
A fundação "Full-Stack": Huawei Ascend & MindSpore
O suporte crítico por trás dessa conquista é a base de poder de computação doméstica construída pela Huawei.
Ao contrário da maioria dos modelos de IA anteriores que dependiam fortemente de GPUs estrangeiras (principalmente Nvidia) para treinamento, o GLM-Image executou todo o seu ciclo de vida — do pré-processamento de dados ao treinamento em grande escala — em chips Huawei Ascend 800T A2 e no framework de IA MindSpore.
Essa combinação totalmente autônoma de "hardware + framework" é a verdadeira notícia aqui. Ela aborda o problema central de "gargalo" no desenvolvimento de IA, provando que treinar modelos de estado da arte (SOTA) é possível sem depender do ecossistema CUDA. A série Ascend 910B (que impulsiona o 800T A2) demonstrou desempenho formidável em ambientes de grandes clusters, oferecendo uma alternativa viável para a comunidade global de código aberto.
Desconstruindo a Arquitetura: Por que AR + Difusão importa
A Zhipu AI também alcançou inovação significativa na arquitetura do modelo. O GLM-Image se afastou das rotas técnicas padrão usadas por muitos modelos de código aberto ocidentais.
Em vez disso, utiliza uma arquitetura híbrida de "Autorregressivo (AR) + Decodificador de Difusão".
- O "Cérebro" (Autorregressivo): Um modelo AR de 9 bilhões (9B) de parâmetros lida com a compreensão de instruções complexas, planejamento de layout e geração de texto dentro das imagens.
- O "Pintor" (Difusão): Um modelo de difusão de 7 bilhões (7B) de parâmetros atua como o decodificador, preenchendo detalhes de alta fidelidade com base no projeto do modelo AR.
Essa abordagem resolve uma dor notória na geração de imagens por IA: a renderização precisa de texto. Anteriormente, imagens geradas por IA frequentemente apresentavam texto distorcido e ilegível. Graças às fortes capacidades cognitivas do componente AR, o GLM-Image alcançou a maior precisão na geração de caracteres chineses entre os modelos de código aberto.
Esse caminho técnico — priorizando a compreensão cognitiva antes da geração — espelha a abordagem vista em modelos avançados de raciocínio cognitivo como o Nano Banana Pro, que se centra em "conhecimento + raciocínio" para lidar com tarefas complexas com maior precisão do que os modelos generativos padrão.
Reação do Mercado: A ascensão da Knowledge Atlas (2513.HK)
O valor "padrão-ouro" de liderar o gráfico global foi imediatamente refletido nas reações do mercado de capitais. Quando a notícia da abertura do código do GLM-Image foi divulgada, o preço das ações da entidade controladora da Zhipu AI, Knowledge Atlas (2513.HK), subiu mais de 16% em um único dia. Os investidores reconheceram claramente o valor de longo prazo da combinação "chip doméstico + modelo autônomo".
De fato, desde sua listagem na Bolsa de Valores de Hong Kong em 8 de janeiro como a "primeira ação global de grandes modelos", a Knowledge Atlas viu o preço de suas ações aumentar mais de 100%.
Democratizando o Design de IA: Código Aberto para Todos
De uma perspectiva de longo prazo, o sucesso do GLM-Image é impulsionado pela sinergia de toda uma cadeia industrial. Essa capacidade de cadeia completa não serve apenas aos gigantes da tecnologia; ela reduz significativamente as barreiras para pequenas e médias empresas (PMEs).
Com custos de inferência tão baixos quanto 0,1 RMB (aprox. 0,01 USD) por imagem, o GLM-Image permite que as empresas utilizem ferramentas de design de IA de primeira linha por uma fração dos custos tradicionais.
Hoje, o código-fonte e os pesos para o GLM-Image estão disponíveis de forma síncrona no GitHub e no Hugging Face. Desenvolvedores em todo o mundo agora podem usar livremente esta "solução totalmente autônoma", quebrando a narrativa tradicional de que o treinamento de modelos de ponta depende apenas do silício dos EUA.

Por que o Seedance 2.0 foi removido? A verdade por trás do vídeo da StormCrew e a derrota do Kling 3.0
A análise da StormCrew causou o banimento por pânico do Seedance 2.0. Descubra por que seu custo-benefício 10x e tecnologia de destilação estão esmagando o Kling 3.0.

Kling 3 Just Dropped: Will Wan 3 Be the Next Big Shock? (The AI Video Arms Race)
A guerra dos vídeos de IA está esquentando. Com o Kling 3 estabelecendo um novo padrão, analisamos a rivalidade, a história das Batalhas de Áudio e prevemos o que o Wan 3 precisa fazer para sobreviver.
Kling 3 4k Vs Pro
SEO-friendly description for search engines
Kling 3 4k Workflow
SEO-friendly description for search engines
Kling 3 Native 4k
SEO-friendly description for search engines
HappyHorse AI Video Generator: o que o novo modelo pode fazer
Conheça o HappyHorse, um novo modelo de geração de vídeo com text-to-video, image-to-video, video-to-video, áudio nativo e fluxos pensados para criadores.

Wan 2.7 Image Meets Kling 2.6: The Ultimate AI Visual Workflow
Descubra como os recursos avançados de edição e renderização de texto em 3K do novo modelo Wan 2.7 Image criam o pipeline de ativos perfeito para a geração de vídeos do Kling 2.6.
The Next Generation of Generation: Unpacking the Wan 2.7 Upgrade
The highly anticipated Wan 2.7 Video release marks a turning point, introducing a multi-modal injection system and a studio-grade workflow for creators.