
Nvidia 독점 타파: GLM-Image와 화웨이 Ascend 칩이 글로벌 AI 차트를 석권한 방법
1월 14일, 글로벌 인공지능 업계에 지각변동이 일어나 산업계와 전 세계 자본 시장의 이목을 집중시켰습니다. Zhipu AI(지푸 AI)와 화웨이가 공동 개발한 멀티모달 이미지 생성 모델인 GLM-Image가 Hugging Face(허깅페이스) 트렌딩 리스트 1위에 등극했습니다.
Hugging Face는 오픈소스 모델의 "만국박람회"와 같은 곳으로, 글로벌 거대 기업과 개발자들이 최고의 AI 도구를 선보이는 핵심 허브입니다. 이곳의 트렌딩 리스트 정상을 차지한 것은 세계 최고의 테크 컨퍼런스에서 메인 무대에 서는 것과 같으며, GLM-Image의 기술력과 응용 가치가 국제적으로 인정받았음을 의미합니다.
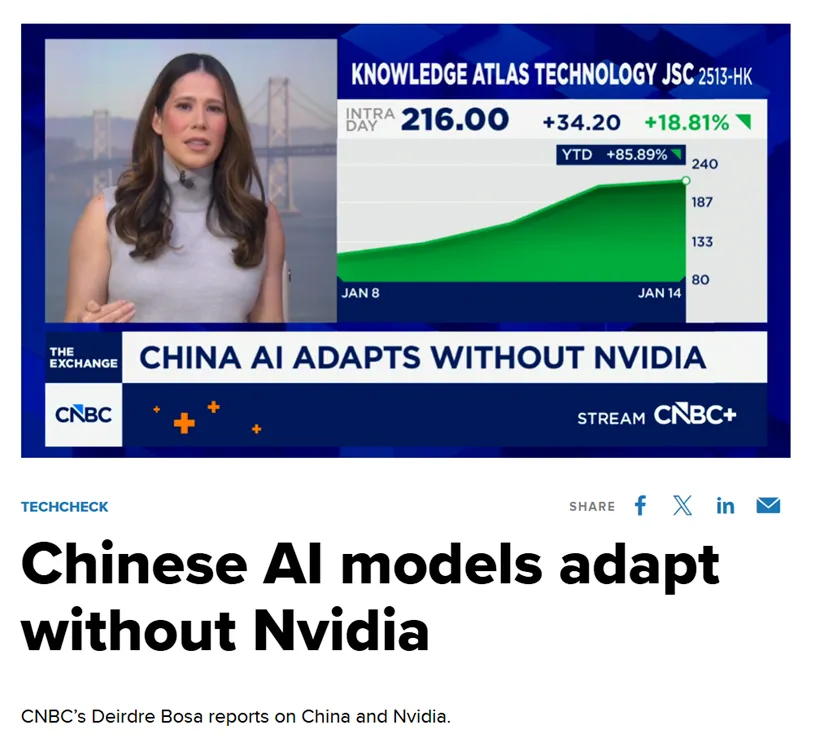
미국 매체 CNBC는 Zhipu와 화웨이가 훈련시킨 이 최신 모델이 미국 칩에 대한 의존이라는 "신화를 효과적으로 깨뜨렸다"고 지적했습니다. 이 성과는 우연이 아니며, 중국 국내 AI 산업 체인 전반에 걸친 깊은 "소프트웨어-하드웨어 시너지"와 기술적 돌파구의 필연적인 결과입니다.
"풀스택" 기반: 화웨이 Ascend & MindSpore
이 성과의 핵심적인 뒷받침은 화웨이가 구축한 국산 연산 능력 기반입니다.
훈련을 위해 외국산 GPU(주로 Nvidia)에 크게 의존했던 기존의 대부분 AI 모델과 달리, GLM-Image는 데이터 전처리부터 대규모 훈련에 이르는 전체 수명 주기를 화웨이의 Ascend(승등) 800T A2 칩과 MindSpore(승사) AI 프레임워크 상에서 실행했습니다.
이 완전 자율적인 "하드웨어 + 프레임워크" 조합이야말로 진짜 주목해야 할 점입니다. 이는 AI 개발의 핵심적인 "병목" 문제를 해결하며, CUDA 생태계에 의존하지 않고도 최첨단(SOTA) 모델 훈련이 가능하다는 것을 증명했습니다. Ascend 910B 시리즈(800T A2의 기반)는 대규모 클러스터 환경에서 강력한 성능을 입증하며 글로벌 오픈소스 커뮤니티에 실질적인 대안을 제공하고 있습니다.
아키텍처 해부: 왜 AR + Diffusion인가?
Zhipu AI는 모델 아키텍처에서도 중요한 혁신을 달성했습니다. GLM-Image는 많은 서구 오픈소스 모델이 사용하는 표준 기술 경로를 따르지 않았습니다.
대신, 하이브리드 "자기회귀(AR) + 확산(Diffusion) 디코더" 아키텍처를 채택했습니다.
- "두뇌" (Autoregressive): 90억(9B) 파라미터의 AR 모델이 복잡한 지시 이해, 레이아웃 계획, 이미지 내 텍스트 생성을 담당합니다.
- "화가" (Diffusion): 70억(7B) 파라미터의 확산 모델이 디코더 역할을 하여, AR 모델의 청사진을 바탕으로 고해상도 디테일을 채워 넣습니다.
이 접근 방식은 AI 이미지 생성의 고질적인 문제인 '정확한 텍스트 렌더링'을 해결합니다. 이전에는 AI가 생성한 이미지의 텍스트가 깨지거나 읽을 수 없는 경우가 많았습니다. AR 구성 요소의 강력한 인지 능력 덕분에 GLM-Image는 오픈소스 모델 중 한자 생성에서 최고의 정확도를 달성했습니다.
생성 이전에 인지적 이해를 우선시하는 이 기술적 경로는 Nano Banana Pro와 같은 고급 인지 추론 모델에서 볼 수 있는 접근 방식과 일치합니다. Nano Banana Pro 역시 "지식 + 추론"을 중심으로 두어 표준 생성 모델보다 복잡한 작업을 더 정밀하게 처리합니다.
시장 반응: Knowledge Atlas (2513.HK)의 급등
글로벌 차트 1위라는 "골드 스탠다드" 가치는 즉각적으로 자본 시장의 반응에 반영되었습니다. GLM-Image의 오픈소스화 소식이 처음 전해졌을 때, Zhipu AI의 모체인 Knowledge Atlas (2513.HK) 의 주가는 하루 만에 16% 이상 급등했습니다. 투자자들은 "국산 칩 + 자율 모델" 조합의 장기적 가치를 분명히 인식했습니다.
실제로, 1월 8일 "글로벌 거대 모델 첫 주식"으로 홍콩 증권거래소에 상장된 이후 Knowledge Atlas의 주가는 100% 이상 상승했습니다.
AI 디자인의 민주화: 모두를 위한 오픈소스
장기적인 관점에서 볼 때, GLM-Image의 성공은 전체 산업 체인의 시너지에 의해 주도됩니다. 이 풀체인 역량은 거대 기술 기업만을 위한 것이 아니라, 중소기업(SME)의 진입 장벽을 크게 낮춥니다.
이미지당 0.1 위안(약 0.01 USD) 이라는 저렴한 추론 비용으로, 기업들은 기존 비용의 일부만으로 최고 수준의 AI 디자인 도구를 활용할 수 있게 되었습니다.
오늘날 GLM-Image의 소스 코드와 가중치는 GitHub와 Hugging Face 모두에서 동기적으로 사용할 수 있습니다. 전 세계 개발자들은 이제 이 "완전 자율 솔루션"을 자유롭게 사용하여, 최첨단 모델 훈련이 미국 실리콘에만 의존한다는 전통적인 서사를 깨뜨릴 수 있게 되었습니다.

Seedance 2.0은 왜 삭제되었나? StormCrew 영상의 진실과 Kling 3.0의 몰락
StormCrew의 리뷰가 Seedance 2.0의 '패닉 밴'을 불렀다. 10배 가성비와 증류 기술이 Kling 3.0을 압살하는 이유를 공개한다.

Kling 3 Just Dropped: Will Wan 3 Be the Next Big Shock? (The AI Video Arms Race)
AI 비디오 전쟁이 가열되고 있습니다. Kling 3가 새로운 기준을 세운 지금, 우리는 이 라이벌 관계와 오디오 전쟁의 역사를 분석하고, Wan 3가 살아남기 위해 무엇을 해야 하는지 예측해 봅니다.
Kling 3 4k Vs Pro
SEO-friendly description for search engines
Kling 3 4k Workflow
SEO-friendly description for search engines
Kling 3 Native 4k
SEO-friendly description for search engines
HappyHorse AI Video Generator: 새 모델은 무엇을 할 수 있나
HappyHorse는 text-to-video, image-to-video, video-to-video, 네이티브 오디오, 그리고 크리에이터 중심 워크플로를 제공하는 새로운 AI 비디오 생성 모델입니다.

Wan 2.7 Image Meets Kling 2.6: The Ultimate AI Visual Workflow
새로운 Wan 2.7 Image 모델의 고급 편집 및 3K 텍스트 렌더링 기능이 Kling 2.6 비디오 생성을 위한 완벽한 에셋 파이프라인을 어떻게 구축하는지 알아보세요.
The Next Generation of Generation: Unpacking the Wan 2.7 Upgrade
The highly anticipated Wan 2.7 Video release marks a turning point, introducing a multi-modal injection system and a studio-grade workflow for creators.