
Rompere il monopolio Nvidia: come GLM-Image e il chip Huawei Ascend hanno conquistato le classifiche AI
Il 14 gennaio si è verificato un cambiamento sismico nel panorama globale dell'intelligenza artificiale, catturando l'attenzione sia degli attori industriali che dei mercati dei capitali di tutto il mondo. GLM-Image, un modello di generazione di immagini multimodale sviluppato congiuntamente da Zhipu AI e Huawei, è salito al primo posto nella lista Trending di Hugging Face.
Per i non addetti ai lavori, Hugging Face è essenzialmente l'"Esposizione Universale" dei modelli open source: un hub centrale dove giganti internazionali e sviluppatori mostrano i loro migliori strumenti di AI. Raggiungere la vetta della sua lista Trending è come occupare il palco principale alla più importante conferenza tecnologica del mondo, a significare il riconoscimento internazionale della prodezza tecnica e del valore applicativo di GLM-Image.
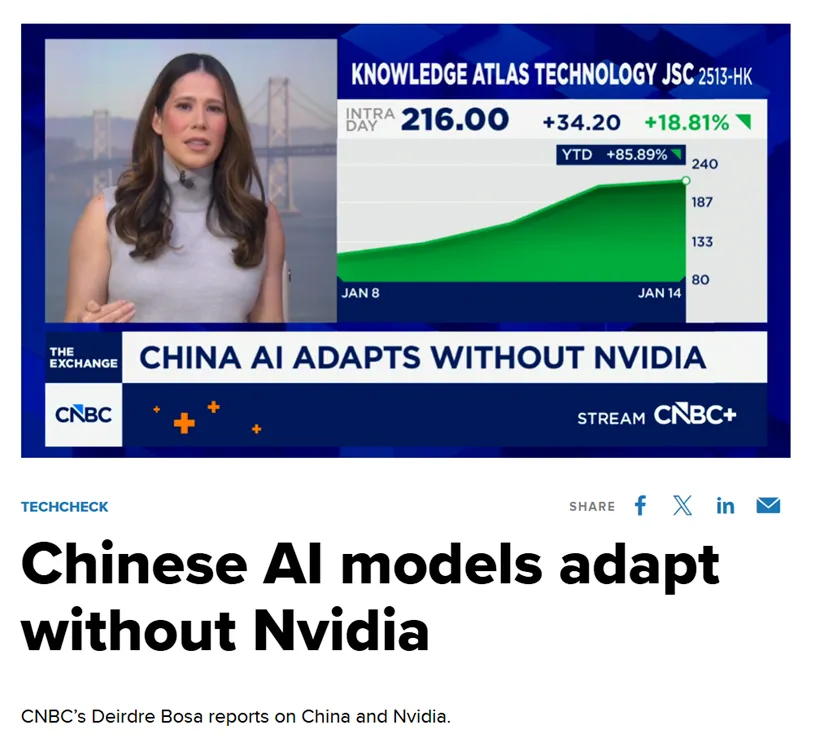
L'emittente statunitense CNBC ha notato che questo modello avanzato, addestrato da Zhipu e Huawei, "infrange efficacemente il mito" della dipendenza dai chip statunitensi. Questo risultato non è accidentale; è il risultato inevitabile di una profonda "sinergia software-hardware" e di una svolta nell'intera catena industriale nazionale dell'AI in Cina.
Le fondamenta "Full-Stack": Huawei Ascend & MindSpore
Il supporto critico dietro questo risultato è la fondazione di potenza di calcolo nazionale costruita da Huawei.
A differenza della maggior parte dei precedenti modelli di AI che si affidavano pesantemente a GPU straniere (principalmente Nvidia) per l'addestramento, GLM-Image ha eseguito l'intero ciclo di vita — dalla pre-elaborazione dei dati all'addestramento su vasta scala — su chip Huawei Ascend 800T A2 e sul framework AI MindSpore.
Questa combinazione completamente autonoma "hardware + framework" è la vera notizia qui. Risolve il problema centrale del "collo di bottiglia" nello sviluppo dell'AI, dimostrando che l'addestramento di modelli all'avanguardia (SOTA) è possibile senza fare affidamento sull'ecosistema CUDA. La serie Ascend 910B (che alimenta l'800T A2) ha dimostrato prestazioni formidabili in ambienti cluster di grandi dimensioni, offrendo un'alternativa praticabile alla comunità open source globale.
Decostruire l'architettura: Perché AR + Diffusione è importante
Zhipu AI ha anche ottenuto un'innovazione significativa nell'architettura del modello. GLM-Image si è discostato dai percorsi tecnici standard utilizzati da molti modelli open source occidentali.
Invece, utilizza un'architettura ibrida "Autoregressivo (AR) + Decoder a Diffusione".
- Il "Cervello" (Autoregressivo): Un modello AR da 9 miliardi (9B) di parametri gestisce la comprensione di istruzioni complesse, la pianificazione del layout e la generazione di testo all'interno delle immagini.
- Il "Pittore" (Diffusione): Un modello di diffusione da 7 miliardi (7B) di parametri agisce come decoder, riempiendo dettagli ad alta fedeltà basati sul progetto del modello AR.
Questo approccio risolve un noto punto dolente nella generazione di immagini AI: il rendering accurato del testo. In precedenza, le immagini generate dall'AI presentavano spesso testo confuso e illeggibile. Grazie alle forti capacità cognitive del componente AR, GLM-Image ha raggiunto la massima precisione nella generazione di caratteri cinesi tra i modelli open source.
Questo percorso tecnico — dare priorità alla comprensione cognitiva prima della generazione — rispecchia l'approccio visto nei modelli avanzati di ragionamento cognitivo come Nano Banana Pro, che si concentra su "conoscenza + ragionamento" per gestire compiti complessi con maggiore precisione rispetto ai modelli generativi standard.
Reazione del mercato: L'ascesa di Knowledge Atlas (2513.HK)
Il valore "standard aureo" di guidare la classifica globale si è riflesso immediatamente nelle reazioni del mercato dei capitali. Quando si è diffusa la notizia del rilascio open source di GLM-Image, il prezzo delle azioni dell'entità madre di Zhipu AI, Knowledge Atlas (2513.HK), è aumentato di oltre il 16% in un solo giorno. Gli investitori hanno chiaramente riconosciuto il valore a lungo termine della combinazione "chip nazionale + modello autonomo".
Infatti, dalla sua quotazione alla Borsa di Hong Kong l'8 gennaio come il "primo titolo globale di grandi modelli", Knowledge Atlas ha visto il prezzo delle sue azioni aumentare di oltre il 100%.
Democratizzare il design AI: Open Source per tutti
Da una prospettiva a lungo termine, il successo di GLM-Image è guidato dalla sinergia di un'intera catena industriale. Questa capacità a catena completa non serve solo i giganti della tecnologia; abbassa significativamente le barriere per le piccole e medie imprese (PMI).
Con costi di inferenza bassi come 0,1 RMB (circa 0,01 USD) per immagine, GLM-Image consente alle aziende di utilizzare strumenti di progettazione AI di alto livello a una frazione dei costi tradizionali.
Oggi, il codice sorgente e i pesi per GLM-Image sono disponibili in modo sincrono su GitHub e Hugging Face. Gli sviluppatori di tutto il mondo possono ora utilizzare liberamente questa "soluzione completamente autonoma", rompendo la narrazione tradizionale secondo cui l'addestramento di modelli all'avanguardia dipende esclusivamente dal silicio statunitense.

Perché Seedance 2.0 è stato rimosso? La verità dietro il video di StormCrew & la sconfitta di Kling 3.0
La recensione di StormCrew ha causato il ban da panico di Seedance 2.0. Scopri perché la sua efficienza 10x e la tecnologia di distillazione stanno schiacciando Kling 3.0.

Kling 3 Just Dropped: Will Wan 3 Be the Next Big Shock? (The AI Video Arms Race)
La guerra dei video AI si sta scaldando. Con Kling 3 che stabilisce un nuovo standard, analizziamo la rivalità, la storia delle Audio Battles, e prevediamo cosa deve fare Wan 3 per sopravvivere.
Kling 3 4k Vs Pro
SEO-friendly description for search engines
Kling 3 4k Workflow
SEO-friendly description for search engines
Kling 3 Native 4k
SEO-friendly description for search engines
HappyHorse AI Video Generator: cosa può fare il nuovo modello
Scopri HappyHorse, un nuovo modello di generazione video con text-to-video, image-to-video, video-to-video, audio nativo e flussi pensati per i creator.

Wan 2.7 Image Meets Kling 2.6: The Ultimate AI Visual Workflow
Scopri come le funzionalità avanzate di editing e rendering del testo 3K del nuovo modello Wan 2.7 Image creano la pipeline di risorse perfetta per la generazione di video Kling 2.6.
The Next Generation of Generation: Unpacking the Wan 2.7 Upgrade
The highly anticipated Wan 2.7 Video release marks a turning point, introducing a multi-modal injection system and a studio-grade workflow for creators.